Handwritten Text Recognition using TensorFlow 2.0
An easy-to-use implementation of offline HTR system (line-level)

How long my friend. Hope you’re fine. This time I bring to you a new project/post. Now with offline Handwritten Text Recognition (line-level), basic concepts, state-of-art models, my new proposed model, results and conclusions. All this using TensorFlow 2.0, through an easy-to-use code.
Firstly, I would like to thank the readers of the other posts and contacts I had. Feel free to contact me, I will help you whenever possible. Secondly, even with this title name, this post will have no code and no technical approach (maybe I’ve lied here), but rather a description of the project development and some points that I find interesting.
For more detail, you can read the project presentation, well as other approaches used with a little more in depth. In addition, for code lovers, you can also find the open source, documentation and even a tutorial:
Introduction
For those starting in the Optical Character Recognition (OCR) environment, I find it interesting to bring a brief context.
According to [1], OCR systems have two categories: online, in which input information is obtained through real-time writing sensors; and offline, in which input information is obtained through static information (images). Within the offline category, there is the recognition of typed and manuscript text (Figure 1).

So, Handwritten Text Recognition (HTR) has the purpose of transcribing cursive text to the digital medium (ASCII, Unicode) [2].
For many years, HTR systems have used the Hidden Markov Models (HMM) for the transcription task [3]–[5], but recently, through Deep Learning, the Convolutional Recurrent Neural Networks (CRNN) approach has been used to overcome some limitations of HMM [6], [7]. To exemplify a CRNN model, I bring the [8] model (Figure 2).
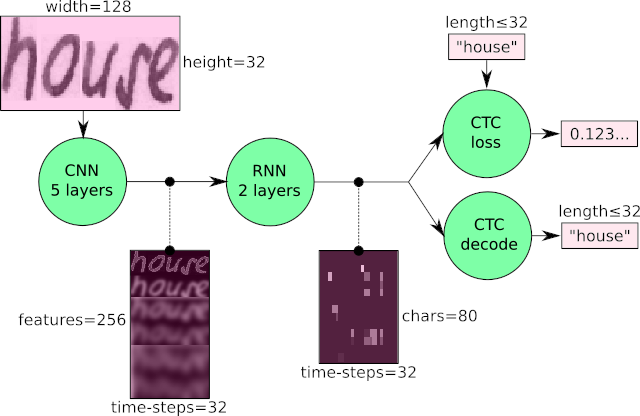
The workflow can be divided into 3 steps. Step 1: the input image is fed into the CNN layers to extract features. The output is a feature map. Step 2: through the implementation of Long Short-Term Memory (LSTM), the RNN is able to propagate information over longer distances and provide more robust features to training. Step 3: with RNN output matrix, the Connectionist Temporal Classification (CTC) [9] calculates loss value and also decodes into the final text.
For more detail on this process, I recommend reading Build a Handwritten Text Recognition System using TensorFlow by Harald Scheidl (2018).
Lastly, is very important explain that for this post, step 3 (CTC) is the same for all architectures presented, then the Vanilla Beam Search [10] method is used, since it doesn’t require a dictionary for its application, unlike other known methods such as Token Passing [11] and Word Beam Search [8]. Therefore, the architectures presented in the following sections only act in steps 1 and 2.
In addition, the charset for encoding text is also the same for all datasets. So, the list used consists of 95 printable characters from ASCII table (Figure 3) by default and doesn’t contain accented letters.

Now you might be wondering why use the same CTC and charset for the architectures and datasets. Well, for this experiment purposefully, I wanted to bring a more uniform approach between the models and databases. Since the use of specific dictionaries and charsets can bring better results in some scenarios, but not so much in others. For example, a charset with only 60 characters is “easier to hit” (1/60) than another with 125 (1/125). In fact, the approach here becomes more difficult for text recognition by the models.
Datasets
For the experiment, it was used the free segmentation approach of text lines of Bentham, IAM, Rimes and Saint Gall datasets.
The methodology of partitioning (training, validation and test) of the data was kept original for each dataset, except for Rimes, since it doesn’t have the validation partition. For this case, the validation data is a subset of 10% of the training partition.
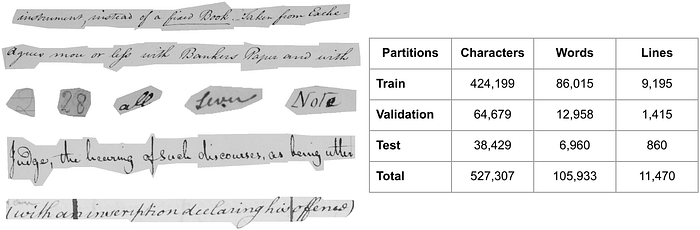
Bringing a brief detailing of each dataset, Bentham [12] is a collection of manuscripts written by English philosopher Jeremy Bentham (1748–1832). This historical dataset (Figure 4) is the most complex among the four adopted. It also has a considerable amount of punctuation marks in the texts.
The Institut für Informatik und Angewandte Mathematik (IAM) database [13] contains forms with English manuscripts, which can be considered as a simple base, since it has a good quality for text recognition (Figure 5). However, it brings the challenge of having several writers, that is, the cursive style is unrestricted.

The Reconnaissance et Indexation de données Manuscrites et de fac similÉS (Rimes) database [14] is a collection of text written in French language by several writers (Figure 6). The text recognition is also considered easy because there is a good writing of the texts, however, the French language brings more accented words.

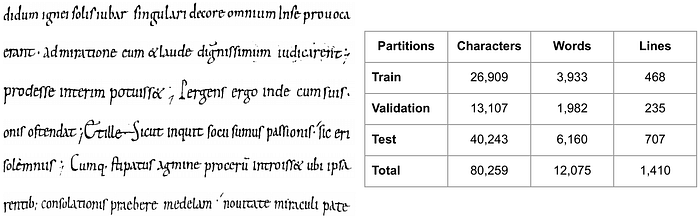
Lastly, the Saint Gall database [15] brings manuscripts in Latin from the 9th century of only one writer (Figure 7). The images obtained are already binarized and normalized and the biggest challenge for this collection is to deal with overfitting, since it has around 1,400 text lines in total and the writing style is very regular.
In short, each explored database brings a certain challenge. I know that there are specific techniques to solve each of these challenges, but the purpose of the study is to bring methods and approaches that are common to the all datasets presented (just to remember).
Finally, to make an easy input of the data into model, the project was prepared to transform each dataset. The transformation process is simple. It put already preprocessed images, ground truth texts and encoded texts into only one HDF5 file. This possibility a fast loading of the data, easy uploading to Google Drive (if you run there) and decreases the storage space (e.g. dataset with 2.8gb becomes 360mb).
Architectures
I chose two model approaches from state-of-art as inspiration for mine. However, I won’t go into the smallest details of each one, but I will leave some important points and, of course, references of the works.
I would also like to comment that the architectures I chose, correspond to approaches that use BLSTM in the recurrent layer (RNN) and that were eventually compared with MDLSTM [16] as an alternative to computational cost and high complexity. If you are interested in the details and approaches used in each study, I recommend the readings:
- Are multidimensional recurrent layers really necessary for handwritten text recognition? (J. Puigcerver, 2017)
- Gated convolutional recurrent neural net- works for multilingual handwriting recognition (T. Bluche and R. Messina, 2017)
In this way, the first architecture (CNN-BLSTM), introduced by Puigcerver [17], has a high level of recognition rate and a large number of parameters (around 9.6 million). The Figure 8 shows in detail the distribution of parameters and hyperparameters through 5 convolutional layers and 5 BLSTM.
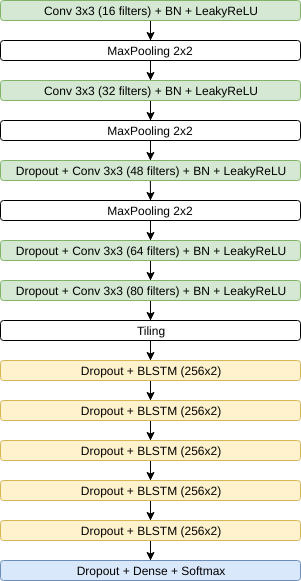
The second architecture (Gated-CNN-BLSTM), now introduced by Bluche and Messina [18], has the highlight of the Gated-CNN approach. In summary, this technique aims to extract more relevant features of the image. Instead Puigcerver approach, this model has very few parameters (around 730 thousand), making it more compact and faster. The Figure 9 shows in detail the distribution of parameters and hyperparameter sthrough 8 convolutional layers (3 gated included) and 2 BLSTM.

Lastly, the proposed architecture (Gated-CNN-BLSTM) that was inspired by [17] and [18], aiming at: (i) to achieve results compatible with Puigcerver model; and (ii) to keep the small number of parameters (not exceeding one million), such as Bluche et al. model.
It was a great challenge to combine the two advantages of each architecture into a single one, however, in the developmental, I applied another Gated approach, once presented by [19] in the context of Language Model. Other methods that also brought differences in results (improvements) were the Batch Renormalization [20] and the Parametric Rectified Linear Unit (PReLU) activator [21].
Thus, the proposed Gated-CNN-BLSTM architecture preserves the low number of parameters (around 820 thousand) and high recognition rate. The Figure 10 shows in detail the distribution of parameters and hyperparameter through 11 convolutional layers (5 gated included) and 2 BLSTM.

For training, it was used the RMSProp optimizer [22] with the standard learning rate of each model to incrementally update the parameters using CTC loss gradients.
Experiment Setup
An important help to this project it was the CTCModel: a Keras Model for Connectionist Temporal Classification [23] repository/paper. In this way, it was possible to abstract the workflow of the HTR system, making easy-to-use code. In short, instead of you worry about the loss value and decoding of outputs (usually in a “manual” way), just call the training and prediction methods as in the Keras, in this case, TensorFlow Keras. Simple like that.
So, each model was trained to minimize the validation loss value of the CTC function. To improve and normalize images, it was applied two techniques in the preprocessing: (i) Illumination Compensation [24] to remove shadows and balance brightness and contrast; (ii) Deslanting [25] to remove the cursive style. A comparison of the image without/with preprocessing is shown in Figure 11.

Continuing, the 1024x128 resizing (with padding) was also performed on all input images and Data Augmentation application to increase the amount of the training partition through morphological and displacement transformations (only minor variations).
It was set for all the minibatch of 16 size and Early Stopping after 20 epochs without improvement in validation loss value. For the best use of each model, within the 20 tolerance epochs, also used ReduceLRonPlateau schedule [26] with a decay factor of 0.2 after 10 epochs without improvement also in validation loss value.
The metrics used to validate the results, calculated through the Levenshtein Distance [27] between the ground truth and the predictions, are: (i) Character Error Rate (CER), and (ii) Word Error Rate (WER). As expected, the WER results tend to be greater than CER, since it corresponds to the distribution of the error of the characters in words [28].
Finally, all training and predictions were conducted on the Google Colaboratory (Colab) platform. By default, the platform offers Linux operating system, with 12GB ram and Nvidia Tesla T4 GPU 16GB memory (thank you so much, Google ❤).
Results
For all tests, doesn’t apply any kind of post-processing, such as Language Model, but only the CTC decoding in the final text is taken into account (oh yeah). Fortunately, the proposed model achieved good results and there is a discussion to highlight for each dataset.
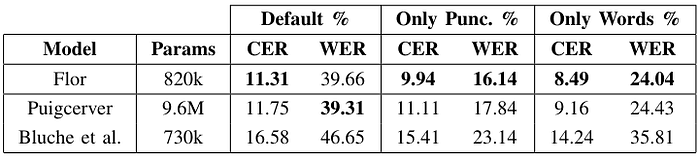
Starting with Bentham dataset, the punctuation marks correspond about 20% of the error rate. In this way, disregarding the punctuation marks, the recognition rate outperforming around 5%. The Table 1 shows the results details between the models in these three scenarios: (i) text without any type of normalization (default); (ii) only punctuation marks; and (iii) text without punctuation marks.
For IAM database, the proposed architecture also achieved better results compared to the others, having an improvement of up to 8%. The details are shown in Table 2.

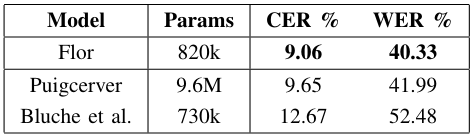
In the Rimes database, punctuation marks don’t influence as much as accent marks used by the French language. In this case, the accent errors are equivalent to about 19% of the error rate. Thus, for both scenarios, the proposed architecture achieved up to 18% improvement. The Table 3 shows the details in both scenarios.

Finally, the Saint Gall database still suffers from overfitting, as expected, and doesn’t have punctuation and accentuation, referring to the Latin language. In this scenario the results were closer, but also got an improvement of up to 6%. Table 4 shows the details of the results.
For this post, I brought brief information about the results. However, if you are interested, there are more details in the GitHub repository (doc folder), or if you prefer, in the project paper.
Conclusions
In this quick post, I presented my recent project on Handwritten Text Recognition (HTR). Overall, after 3 months of study and development, I saw that many HTR projects tend to be very “manual” in model training (when there is code). Of course, traditional Optical Character Recognition (OCR) systems are simpler and by Keras it’s possible to develop easier, for example, in tutorials with the MNIST dataset. However, for HTR this scenario is not the same.
The CTCModel, now I extended to HTRModel, makes development much simpler and more automatic. Anyway, you can check through the tutorial in Jupyter Notebook (you can run through main python file too). I hope at least one of the two codes helps new text recognition projects.
In addition, until arriving at the proposed architecture, many tests were performed (a lot) and even the order of activation and normalization layers influence the results. One approach I haven’t tested is to change the traditional convolutional layers to more specific ones, such as Depthwise Convolutional [29] or Octave Convolutional [30], for example. ~ I leave this tip ~
Thus, let me know if you liked it, or whether it helped or not. Thanks for read until here, see you!
References
[1] M. Sonkusare and N. Sahu, “A survey on handwritten character recognition (hcr) techniques for english alphabets”, Advances in Vision Computing: An International Journal, vol. 3, pp. 1–12, 03 2016.
[2] B. L. D. Bezerra, C. Zanchettin, A. H. Toselli, and G. Pirlo, Handwriting: Recognition, Development and Analysis. Nova Science Pub Inc, jul 2017.
[3] H. Bunke, M. Roth, and E. G. Schukat-Talamazzini, “Off-line cursive handwriting recognition using hidden markov models”, Pattern Recognition, vol. 28, pp. 1399–1413, 09 1995.
[4] B. S. Saritha and S. Hemanth, “An efficient hidden markov model for offline handwritten numeral recognition”, 2010.
[5] A. H. Toselli and E. Vidal, “Handwritten text recognition results on the bentham collection with improved classical n-gram-hmm methods”, in Proceedings of the 3rd International Workshop on Historical Document Imaging and Processing (HIP@ICDAR), 2015.
[6] A. Graves, S. Fernández, M. Liwicki, H. Bunke, and J. Schmidhuber, “Unconstrained on-line handwriting recognition with recurrent neural networks” in Advances in Neural Information Processing Systems 20, vol. 20, 01 2007.
[7] P. Voigtlaender, P. Doetsch, and H. Ney, “Handwriting recognition with large multidimensional long short-term memory recurrent neural networks”, in 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), 10 2016, pp. 228–233.
[8] H. Scheidl, S. Fiel, and R. Sablatnig, “Word beam search: A connectionist temporal classification decoding algorithm”, in 16th International Conference on Frontiers in Handwriting Recognition (ICFHR). Niagara Falls, United States: IEEE Computer Society, 08 2018, pp. 253–258.
[9] A. Graves, S. Fernández, and F. Gomez, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks”, International Conference on Machine Learning, pp. 369–376, 2006.
[10] K. Hwang and W. Sung, “Character-level incremental speech recognition with recurrent neural networks”, 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 3 2016. [Online]. Available: http://dx.doi.org/10.1109/ICASSP.2016.7472696
[11] A. Graves, M. Liwicki, S. Fernández, R. Bertolami, H. Bunke, and J. Schmidhuber, “A novel connectionist system for unconstrained handwriting recognition”, IEEE transactions on pattern analysis and machine intelligence, vol. 31, pp. 855–68, 06 2009.
[12] M. Diem, S. Fiel, F. Kleber, R. Sablatnig, J. M. Saavedra, D. Contreras, J. M. Barrios, and L. S. de Oliveira, “Competition on handwritten digitstring recognition in challenging datasets (hdsrc 2014)”, 14th International Conference on Frontiers in Handwriting Recognition (ICFHR), vol. 2014, 12 2014.
[13] U.-V. Marti and H. Bunke, “The iam-database: An english sentence database for offline handwriting recognition”, International Journal on Document Analysis and Recognition, vol. 5, pp. 39–46, 11 2002.
[14] E. Grosicki, M. Carre, J.-M. Brodin, and E. Geoffrois, “Rimes evaluation campaign for handwritten mail processing”, in ICFHR 2008 : 11th International Conference on Frontiers in Handwriting Recognition. Montreal, Canada: Concordia University, 8 2008, pp. 1–6. [Online]. Available: https://hal.archives-ouvertes.fr/hal-01395332.
[15] A. Fischer, E. Indermühle, H. Bunke, G. Viehhauser, and M. Stolz, “Ground truth creation for handwriting recognition in historical documents”, ACM International Conference Proceeding Series, pp. 3–10, 01 2010.
[16] B. Moysset and R. O. Messina, “Are 2D-LSTM really dead for offline text recognition?” CoRR, vol. abs/1811.10899, 2018.
[17] J. Puigcerver, “Are multidimensional recurrent layers really necessary for handwritten text recognition?” 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), pp. 67–72, 11 2017.
[18] T. Bluche and R. Messina, “Gated convolutional recurrent neural net- works for multilingual handwriting recognition”, 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), pp. 646–651, 11 2017.
[19] Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional networks”, 2017.
[20] S. Ioffe, “Batch renormalization: Towards reducing minibatch
dependence in batch-normalized models”, CoRR, vol. abs/1702.03275,
2017. [Online]. Available: http://arxiv.org/abs/1702.03275
[21] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification”, in 2015 IEEE International Conference on Computer Vision (ICCV), 12 2015, pp. 1026–1034.
[22] T. Tieleman and G. Hinton, “Lecture 6.5–rmsprop: Divide the gradient by a running average of its recent magnitude”, COURSERA: Neural Networks for Machine Learning, 2012.
[23] Y. Soullard, C. Ruffino, and T. Paquet, “CTCModel: Connectionist Temporal Classification in Keras”, 2018.
[24] K.-N. Chen, C.-H. Chen, and C.-C. Chang, “Efficient illumination compensation techniques for text images”, Digital Signal Processing, vol. 22, no. 5, pp. 726–733, 2012. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1051200412000826
[25] A. Vinciarelli and J. Luettin, “A new normalization technique for cursive handwritten words”, Pattern Recognition Letters, vol. 22(9), pp. 1043–1050, 07 2001.
[26] F. Chollet, “Keras: Deep learning library for theano and tensorflow”, 2015.
[27] ] V. Levenshtein, “Binary codes capable of correcting deletions, insertions and reversals”, Soviet Physics Doklady, vol. 10, p. 707, 1966.
[28] J. A. Sánchez, V. Romero, A. H. Toselli, M. Villegas, and E. Vidal, “A set of benchmarks for handwritten text recognition on historical documents”, Pattern Recognition, vol. 94, pp. 122–134, 2019.
[29] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weylan, M. Andreetto, H. Adam, “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”, 2017. [Online]. Available: https://arxiv.org/pdf/1704.04861.pdf
[30] Y. Chen, H. Fan, B. Xu, Z. Yan, Y. Kalantidis, M. Rohrbach, S. Yan, J. Feng, “Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution”, 2019. [Online]. Available: https://arxiv.org/pdf/1904.05049.pdf
